디지털 콘텐츠의 폭증 속에서 사용자에게 적합한 정보를 효과적으로 제공하기 위한 핵심 기술 중 하나가 바로 이다. 이 알고리즘은 사용자 간의 유사성 또는 항목 간의 상관관계를 분석하여 각 개인의 선호도를 예측하고 맞춤형 추천을 가능하게 한다. 특히 협업 필터링은 명시적인 사용자 프로파일 없이도 과거 행동 데이터를 기반으로 정확한 추천을 수행할 수 있다는 장점이 있다. 본 글에서는 이러한 가 어떻게 구성되고, 실생활 서비스에 적용되는지를 심층적으로 살펴본다.
개인화 추천 시스템 알고리즘: 협업 필터링의 작동 방식
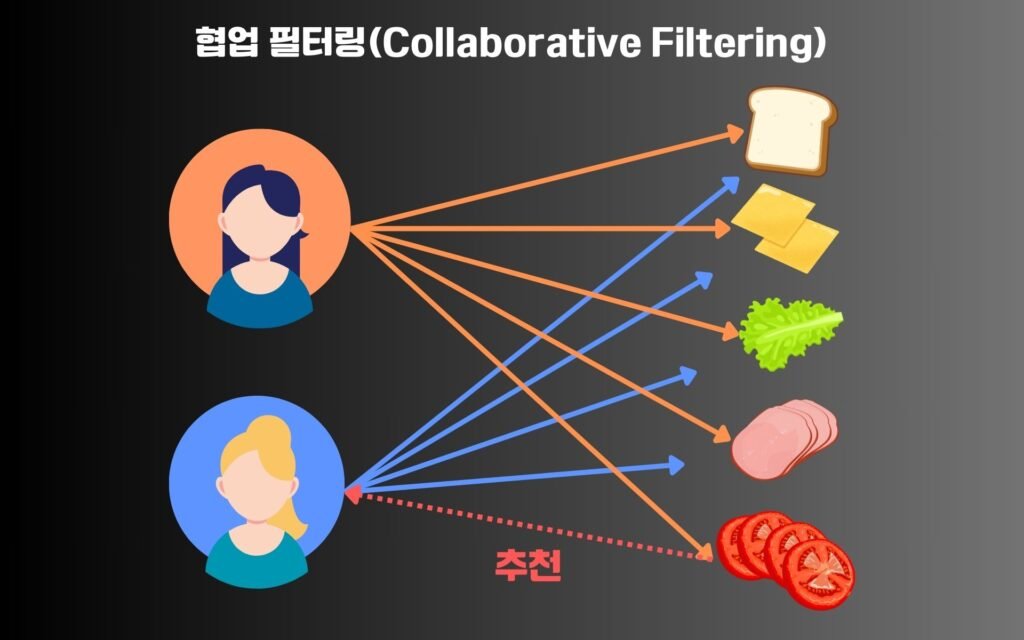
협업 필터링(Collaborative Filtering)은 사용자 간의 유사성 또는 아이템 간의 유사성을 기반으로 사용자에게 맞춤형 콘텐츠를 추천하는 개인화 추천 시스템 알고리즘: 협업 필터링의 원리 중 하나이다. 이 접근 방식은 사용자가 직접 표현하지 않은 선호도를 다른 사용자들의 평가 데이터를 통해 간접적으로 추론한다. 예를 들어, 특정 사용자 A와 유사한 취향을 가진 사용자들이 선호한 영화를 A에게 추천하는 방식이다. 협업 필터링은 명시적인 사용자 프로파일 정보 없이도 높은 정확도의 추천을 가능하게 하며, 대규모 데이터 환경에서도 우수한 성능을 보인다. 하지만 데이터 희소성(Sparsity)과 콜드 스타트(Cold Start) 문제와 같은 한계도 존재한다.
협업 필터링의 기본 개념
협업 필터링은 사용자-아이템 상호작용 데이터(예: 평점, 구매 이력, 클릭 로그 등)를 분석하여 개인화 추천 시스템 알고리즘: 협업 필터링의 원리를 구현한다. 핵심 아이디어는 “비슷한 취향을 가진 사용자들은 비슷한 아이템을 선호한다”는 가정에 기반한다. 이 방식은 크게 두 가지 유형으로 나뉜다: 사용자 기반(User-based)과 아이템 기반(Item-based). 사용자 기반은 유사한 평가 패턴을 가진 사용자 그룹을 찾아 해당 그룹이 선호한 아이템을 추천하며, 아이템 기반은 사용자가 과거에 평가한 아이템과 유사한 다른 아이템을 추천한다.
사용자 기반 협업 필터링
사용자 기반 협업 필터링은 대상 사용자와 유사도가 높은 다른 사용자들을 식별한 후, 그들이 높은 평가를 준 아이템을 추천한다. 유사도 측정에는 피어슨 상관계수(Pearson Correlation Coefficient) 또는 코사인 유사도(Cosine Similarity) 등이 일반적으로 사용된다. 이 방식은 직관적이지만, 사용자 수가 증가함에 따라 계산 복잡도가 급격히 증가하는 단점이 있다. 그럼에도 불구하고 개인화 추천 시스템 알고리즘: 협업 필터링의 원리에 따라 실시간 사용자 행동 데이터를 반영할 수 있어 동적 추천에 유리하다.
아이템 기반 협업 필터링
아이템 기반 협업 필터링은 사용자가 이미 상호작용한 아이템과 유사한 다른 아이템을 추천한다. 이 방법은 아이템 간의 유사도를 미리 계산해 두기 때문에 실시간 추천 속도가 빠르고 시스템 확장성 측면에서 유리하다. 예를 들어, 사용자가 영화 A를 좋아했다면, 영화 A와 유사한 영화 B, C 등을 추천하는 방식이다. 이러한 구조는 개인화 추천 시스템 알고리즘: 협업 필터링의 원리에 따라 안정적인 성능을 제공하며, 특히 아이템 수가 사용자 수보다 적은 환경에서 효과적이다.
협업 필터링의 장단점
협업 필터링의 주요 장점은 명시적인 사용자 정보나 아이템 속성 없이도 정확한 추천이 가능하다는 점이다. 또한, 사용자 행동 데이터만으로도 추천 모델을 구축할 수 있어 적용 범위가 넓다. 그러나 단점으로는 개인화 추천 시스템 알고리즘: 협업 필터링의 원리에서 발생하는 ‘희소성 문제’(많은 사용자-아이템 쌍에 대한 평가 데이터 부족)와 ‘콜드 스타트 문제’(새로운 사용자 또는 아이템에 대한 데이터 부재)가 있다. 이러한 문제를 해결하기 위해 하이브리드 접근법이나 행렬 분해(Matrix Factorization) 기법이 종종 활용된다.
행렬 분해 기반 협업 필터링
행렬 분해는 사용자-아이템 평가 행렬을 저차원의 잠재 요인(Latent Factor) 행렬로 분해하여 사용자와 아이템의 숨겨진 특성을 학습하는 기법이다. 대표적인 방법으로는 SVD(Singular Value Decomposition) 및 ALS(Alternating Least Squares)가 있다. 이 방식은 개인화 추천 시스템 알고리즘: 협업 필터링의 원리를 확장하여 데이터 희소성 문제를 완화하고, 보다 정밀한 추천을 가능하게 한다. 특히, Netflix Prize 대회에서 이 기법이 각광받으며 산업 표준으로 자리 잡았다.
| 구분 | 사용자 기반 협업 필터링 | 아이템 기반 협업 필터링 | 행렬 분해 기반 협업 필터링 |
| 기준 | 유사한 사용자 그룹 | 유사한 아이템 | 잠재 요인(Latent Factor) |
| 장점 | 직관적이고 동적 추천 가능 | 계산 효율성과 확장성 우수 | 희소성 문제 완화, 높은 정확도 |
| 단점 | 계산 복잡도 높음, 확장성 낮음 | 아이템 간 유사도 고정 | 해석 어려움, 초기 학습 시간 소요 |
| 적용 예시 | 소규모 커뮤니티 기반 추천 | e-커머스 상품 추천 | 대규모 스트리밍 서비스 추천 |
사례·비즈니스
협업 필터링이란 무엇인가요?
협업 필터링은 사용자 간의 유사성 또는 아이템 간의 유사성을 기반으로 개인화된 추천을 제공하는 알고리즘입니다. 이 방법은 특정 사용자가 과거에 좋아했던 아이템과 유사한 취향을 가진 다른 사용자들이 선호한 아이템을 추천하거나, 사용자가 평가한 아이템과 유사한 아이템을 제안하는 방식으로 작동합니다.
협업 필터링에는 어떤 유형이 있나요?
협업 필터링은 주로 사용자 기반과 아이템 기반 두 가지 유형으로 구분됩니다. 사용자 기반 협업 필터링은 유사한 선호를 가진 다른 사용자들의 행동을 참고하고, 아이템 기반 협업 필터링은 사용자가 상호작용한 아이템과 유사한 다른 아이템을 기반으로 추천을 생성합니다.
협업 필터링의 주요 장점은 무엇인가요?
협업 필터링은 콘텐츠의 메타데이터 없이도 사용자 행동만으로도 효과적인 추천이 가능하다는 장점이 있습니다. 특히 개인화된 경험을 제공하며, 사용자가 직접 평가하지 않은 새로운 아이템에 대해서도 유의미한 추천을 할 수 있습니다.
협업 필터링의 한계점은 무엇인가요?
협업 필터링은 사용자나 아이템에 대한 충분한 상호작용 데이터가 부족할 경우 성능이 크게 저하되는 콜드 스타트 문제를 겪을 수 있습니다. 또한, 데이터가 희소할 경우 정확한 유사도 계산이 어려워지고, 인기 아이템에 추천이 치우치는 경향이 있습니다.


