데이터 마이닝은 대량의 데이터에서 유의미한 패턴과 정보를 추출하는 핵심 기술로, 산업 분야에서 활용되고 있습니다. 특히 오픈 소스 데이터 마이닝 툴 WEKA는 사용자 친화적인 인터페이스와 강력한 알고리즘을 제공하여 초보자부터 전문가까지 폭넓게 사용할 수 있습니다. 본 기사에서는 를 통해 설치부터 데이터 불러오기, 전처리, 모델 학습 및 평가까지 단계별로 안내합니다. 이를 통해 독자들은 실제 데이터 분석 프로젝트에 WEKA를 효과적으로 적용할 수 있는 기반을 마련할 수 있습니다.
WEKA를 활용한 데이터 마이닝 입문: 오픈 소스 데이터 마이닝 툴 WEKA 사용법 기초 가이드
WEKA(Waikato Environment for Knowledge Analysis)는 뉴질랜드 와이카토 대학교에서 개발한 오픈 소스 데이터 마이닝 툴로, 기계 학습, 데이터 전처리, 시각화, 모델 평가 등 데이터 분석 기능을 제공합니다. 이 도구는 자바 기반으로 개발되어 크로스 플랫폼에서 실행 가능하며, 사용자 친화적인 GUI(Graphical User Interface)를 통해 초보자도 쉽게 접근할 수 있습니다. 본 가이드는 오픈 소스 데이터 마이닝 툴 WEKA 사용법 기초 가이드를 목표로 하여, WEKA 설치부터 간단한 분석 수행까지의 절차를 단계별로 안내합니다.
1. WEKA 설치 및 실행 방법
WEKA는 공식 웹사이트(https://www.cs.waikato.ac.nz/ml/weka/)에서 무료로 다운로드할 수 있습니다. 설치 파일은 운영체제(Windows, macOS, Linux)별로 제공되며, 자바 런타임 환경(JRE)이 사전 설치되어 있어야 정상적으로 작동합니다. 설치 후 WEKA를 실행하면 ‘WEKA GUI Chooser’ 창이 나타나며, 이 창에서는 Explorer, Experimenter, KnowledgeFlow, Simple CLI 등 인터페이스를 선택할 수 있습니다. 초보자라면 데이터 탐색과 모델링이 가능한 Explorer를 사용하는 것이 적합합니다.
2. 데이터 불러오기 및 형식 이해
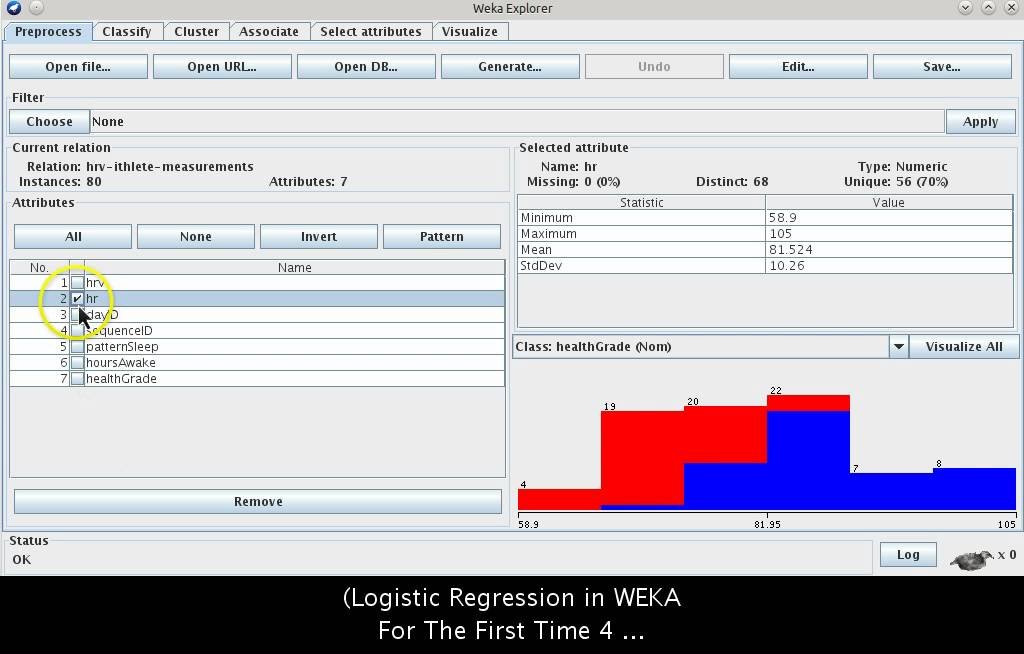
WEKA는 ARFF(Attribute-Relation File Format), CSV, Excel 등 파일 형식을 지원합니다. 가장 기본적인 형식은 WEKA에서 정의한 ARFF이며, 이는 헤더(속성 정의)와 데이터 본문으로 구성됩니다. Explorer 인터페이스에서 ‘Open file’ 버튼을 통해 데이터를 불러오면, 속성(Attribute)과 인스턴스(Instance)가 표 형태로 표시됩니다. 각 속성은 명목형(Nominal) 또는 수치형(Numeric)으로 자동 인식되며, 필요 시 수동으로 수정할 수 있습니다.
3. 데이터 전처리 기능 활용
WEKA의 ‘Preprocess’ 탭에서는 결측치 처리, 정규화, 이산화, 속성 선택 등 데이터 전처리 기능을 제공합니다. ‘Choose’ 버튼을 통해 필터(Filter)를 적용할 수 있으며, 예를 들어 ‘Normalize’ 필터는 수치형 속성을 0~1 범위로 정규화합니다. 전처리 후에는 ‘Apply’ 버튼을 클릭하여 변환된 데이터를 확인할 수 있으며, 이는 후속 분석의 성능 향상에 기여합니다.
4. 분류(Classification) 모델 구축 및 평가
WEKA의 ‘Classify’ 탭에서는 기계 학습 알고리즘(예: J48, Naive Bayes, SVM 등)을 활용해 분류 모델을 훈련하고 평가할 수 있습니다. ‘Classifier’에서 알고리즘을 선택한 후, ‘Test options’에서 교차 검증(Cross-validation) 또는 홀드아웃(Hold-out) 방식으로 모델을 평가합니다. 결과 창에는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 등의 성능 지표가 표시되어 모델의 효율성을 직관적으로 파악할 수 있습니다.
5. 시각화 및 결과 해석
WEKA는 시각화 기능을 통해 데이터 분포, 결정 트리 구조, 혼동 행렬(Confusion Matrix) 등을 그래픽으로 표현합니다. ‘Visualize’ 탭에서는 속성 간 산점도를 확인할 수 있으며, 분류 결과는 그래프나 텍스트 형태로 출력됩니다. 특히, J48 알고리즘을 사용한 경우 트리 구조를 시각적으로 확인할 수 있어 모델의 해석 가능성을 높여줍니다. 이러한 시각화 도구는 오픈 소스 데이터 마이닝 툴 WEKA 사용법 기초 가이드에서 중요한 학습 요소입니다.
| 기능 | WEKA 인터페이스 | 주요 용도 |
| 데이터 불러오기 | Explorer → Preprocess | ARFF, CSV, Excel 파일 로드 |
| 데이터 전처리 | Explorer → Preprocess → Choose | 결측치 처리, 정규화, 속성 변환 |
| 모델 훈련 | Explorer → Classify | 분류, 회귀, 군집 알고리즘 적용 |
| 성능 평가 | Classify → Test options | 정확도, 정밀도, F1 점수 확인 |
| 시각화 | Explorer → Visualize | 산점도, 트리 구조, 혼동 행렬 확인 |
사례·비즈니스
WEKA는 무엇이며, 어떤 용도로 사용되나요?
WEKA(Waikato Environment for Knowledge Analysis)는 뉴질랜드 와이카토 대학교에서 개발한 오픈 소스 데이터 마이닝 툴로, 머신러닝 알고리즘, 데이터 전처리, 분류, 회귀, 군집화, 시각화 기능을 제공합니다. 특히 교육 및 연구 목적으로 널리 사용되며, 사용자 친화적인 GUI를 통해 코딩 없이도 데이터 분석을 수행할 수 있습니다.
WEKA를 설치하려면 어떤 시스템 요구사항이 필요한가요?
WEKA를 실행하려면 자바(JRE 또는 JDK)가 사전에 설치되어 있어야 하며, 현재 운영체제(Windows, macOS, Linux 등)에 관계없이 자바가 지원되는 환경이라면 사용이 가능합니다. 최소한의 하드웨어 사양만 충족되면 되지만, 대용량 데이터셋을 다룰 경우 더 많은 메모리(RAM)와 처리 성능이 유리합니다.
WEKA에서 데이터를 어떻게 불러오고 전처리하나요?
WEKA의 Explorer 인터페이스를 통해 ARFF, CSV, Excel 등 형식의 데이터를 불러올 수 있으며, 결측치 처리, 속성 선택, 데이터 정규화 등 전처리 도구를 제공합니다. 특히 ‘Preprocess’ 탭에서 데이터의 분포 및 통계 정보를 확인하고, 필요한 변환을 손쉽게 적용할 수 있습니다.
WEKA로 모델을 학습하고 평가하려면 어떻게 하나요?
‘Classify’ 탭에서 머신러닝 알고리즘(예: J48, Naive Bayes, SVM 등)을 선택해 모델을 학습시킬 수 있으며, 교차 검증(cross-validation)이나 테스트 데이터셋을 이용해 성능을 평가할 수 있습니다. 결과 창에서는 정확도, 정밀도, 재현율 등의 지표를 통해 모델의 효과를 분석할 수 있습니다.