데이터 과학과 머신러닝 분야에서 분류 문제를 해결하기 위한 핵심 기법 중 하나는 이다. 이 알고리즘은 마치 나무 구조처럼 조건에 따라 데이터를 계층적으로 분기시켜 최종적인 클래스를 예측하는 직관적이고 해석이 쉬운 모델이다. 복잡한 수학적 배경 없이도 결과를 이해할 수 있어 비전문가에게도 유용하며, 도메인에서 널리 적용된다. 본 글에서는 의사결정 나무의 기본 원리, 구축 과정, 장단점 및 실제 사례를 통해 데이터 분류에서의 활용성을 살펴본다.
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류의 기본 원리
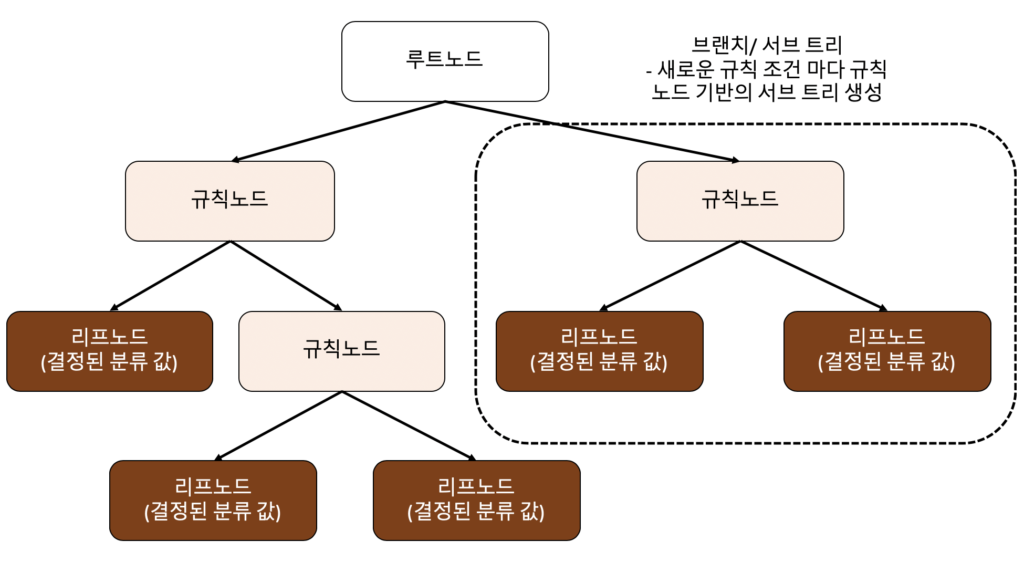
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류는 머신러닝에서 널리 사용되는 지도 학습(supervised learning) 기법 중 하나로, 데이터의 특성(feature)을 기반으로 계층적인 규칙(rule)을 생성하여 범주형 또는 연속형 결과를 예측하는 방식이다. 이 알고리즘은 트리 구조의 분기(decision node)와 단말 노드(leaf node)를 통해 데이터를 재귀적으로 분할하며, 각 분할은 불순도(impurity)를 최소화하는 기준(예: 지니 계수, 엔트로피)에 따라 결정된다. 이러한 구조 덕분에 모델의 해석성이 높고, 복잡한 데이터 관계를 시각적으로 직관적으로 이해할 수 있다는 장점이 있다. 또한, 특성 스케일링이 필요 없고 결측치에 어느 정도 강건하다는 점에서 실무 적용성이 뛰어나다.
의사결정 나무의 작동 원리
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류는 상위 노드에서부터 하위 노드로 내려가며 각 특성 기준으로 데이터를 분할한다. 분할 기준은 일반적으로 지니 불순도(Gini Impurity) 또는 정보 이득(Information Gain)을 기반으로 계산되며, 이는 각 분할이 얼마나 잘 데이터를 동일한 클래스로 구분하는지를 평가한다. 최종적으로 리프 노드(leaf node)에 도달하면 해당 노드에 속한 데이터의 다수 클래스(majority class)가 예측값으로 할당된다. 이 과정은 트리가 과적합(overfitting)되지 않도록 사전 가지치기(pre-pruning) 또는 사후 가지치기(post-pruning) 기법을 적용하여 조절할 수 있다.
의사결정 나무의 장점과 한계
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류는 해석성(interpretability)이 매우 뛰어나다는 점에서 큰 장점을 가진다. 비즈니스 사용자나 도메인 전문가가 모델의 의사결정 과정을 쉽게 이해하고 검증할 수 있다. 또한, 데이터 전처리 요구사항이 낮고 범주형 및 수치형 데이터 모두를 처리할 수 있다. 그러나 단일 트리는 종종 과적합 경향이 있어, 새로운 데이터에 대한 일반화 성능이 떨어질 수 있다. 이러한 한계는 랜덤 포레스트(Random Forest)나 그래디언트 부스팅(Gradient Boosting)과 같은 앙상블 기법을 통해 보완할 수 있다.
핵심 분할 기준: 지니 계수와 엔트로피
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류에서 분할 품질을 평가하기 위해 주로 지니 계수(Gini Index)와 엔트로피(Entropy)를 사용한다. 지니 계수는 무작위로 선택된 두 샘플이 서로 다른 클래스에 속할 확률을 나타내며, 값이 낮을수록 순도가 높다. 엔트로피는 정보 이론에서 유래한 개념으로, 불확실성의 정도를 측정하며, 엔트로피가 낮을수록 더 균일한 클래스 분포를 의미한다. 두 지표 모두 최적의 분할을 찾기 위해 사용되며, 실무에서는 지니 계수가 계산 속도가 빨라 일반적으로 선호된다.
의사결정 나무의 시각화와 해석
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류 결과는 트리 구조로 시각화할 수 있어 결정 경로(decision path)를 명확히 파악할 수 있다. 예를 들어, 고객 이탈 예측 모델에서 ‘최근 구매일수가 30일 이상이고, 총 구매 횟수가 5회 미만인 경우 이탈 확률이 높다’는 규칙을 직관적으로 확인할 수 있다. Python의 scikit-learn 라이브러리는 plot tree나 export graphviz 기능을 통해 이러한 시각화를 지원하며, 도메인 지식과 결합하여 비즈니스 인사이트 도출에 매우 유용하다.
의사결정 나무 모델의 성능 평가 지표
의사결정 나무(Decision Tree) 알고리즘을 활용한 데이터 분류 모델의 성능은 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수(F1-Score) 등 지표로 평가된다. 특히 불균형 데이터의 경우 정확도보다는 재현율이나 F1 점수가 더 신뢰할 수 있는 평가 기준이 된다. 또한, 교차 검증(cross-validation)을 통해 모델의 일반화 성능을 보다 객관적으로 평가할 수 있으며, 혼동 행렬(confusion matrix)을 활용하면 각 클래스별 예측 성능을 세부적으로 분석할 수 있다.
| 평가 지표 | 정의 | 의사결정 나무 적용 시 고려사항 |
| 정확도 (Accuracy) | 전체 예측 중 올바른 예측의 비율 | 클래스 불균형 시 신뢰도 낮음 |
| 정밀도 (Precision) | 양성으로 예측한 것 중 실제 양성의 비율 | 거짓 양성(False Positive) 최소화 필요 시 유용 |
| 재현율 (Recall) | 실제 양성 중 올바르게 예측한 비율 | 거짓 음성(False Negative) 최소화 필요 시 중요 |
| F1 점수 (F1-Score) | 정밀도와 재현율의 조화 평균 | 불균형 데이터에서 균형 잡힌 평가 가능 |
| ROC-AUC | 민감도와 특이도의 균형 평가 지표 | 이진 분류 성능의 전반적 품질 평가에 적합 |
사례·비즈니스
의사결정 나무 알고리즘은 어떤 원리로 데이터를 분류하나요?
의사결정 나무 알고리즘은 입력 데이터의 특성(feature)을 기반으로 일련의 조건절을 통해 분기하여 최종적으로 클래스 레이블을 예측합니다. 각 노드는 특정 특성에 대한 조건을 나타내며, 리프 노드에서 최종 분류 결과가 도출됩니다.
의사결정 나무에서 과적합(overfitting)을 방지하는 방법은 무엇인가요?
과적합을 방지하기 위해 가지치기(pruning) 기법을 사용하거나, 트리의 최대 깊이를 제한하고, 최소 샘플 분할 수 또는 최소 리프 노드 샘플 수와 같은 하이퍼파라미터를 조정합니다. 이를 통해 모델의 일반화 성능을 향상시킬 수 있습니다.
의사결정 나무 알고리즘의 장점은 무엇인가요?
의사결정 나무는 결과 해석이 직관적이며, 데이터 전처리가 상대적으로 간단하고, 비선형 관계도 잘 모델링할 수 있습니다. 또한 특성 중요도를 쉽게 도출할 수 있어 분석에 유용합니다.
의사결정 나무는 연속형과 범주형 데이터 모두를 처리할 수 있나요?
의사결정 나무는 연속형과 범주형 데이터를 모두 처리할 수 있습니다. 연속형 데이터는 임계값을 기준으로 분할되고, 범주형 데이터는 가능한 값들의 조합을 기반으로 분기됩니다. 이는 알고리즘의 유연성을 높여줍니다.


