현대 웹 애플리케이션 개발에서 GraphQL은 클라이언트가 필요한 데이터만 정확히 요청할 수 있도록 해주는 강력한 쿼리 언어로 각광받고 있다. 그러나 잘못 설계된 GraphQL API는 오히려 데이터 과잉 요청, 즉 오버페칭(over-fetching) 문제를 야기할 수 있으며, 이는 성능 저하와 리소스 낭비로 이어진다. 본 글인 ‘’에서는 효율적인 GraphQL API 설계를 위한 핵심 원칙과 실용적인 전략을 제시한다. 이를 통해 개발자들은 불필요한 데이터 전송을 줄이고, 네트워크 성능을 최적화하며, 유지보수하기 쉬운 API를 구축할 수 있다.
GraphQL API 설계에서 오버페칭을 방지하는 핵심 전략
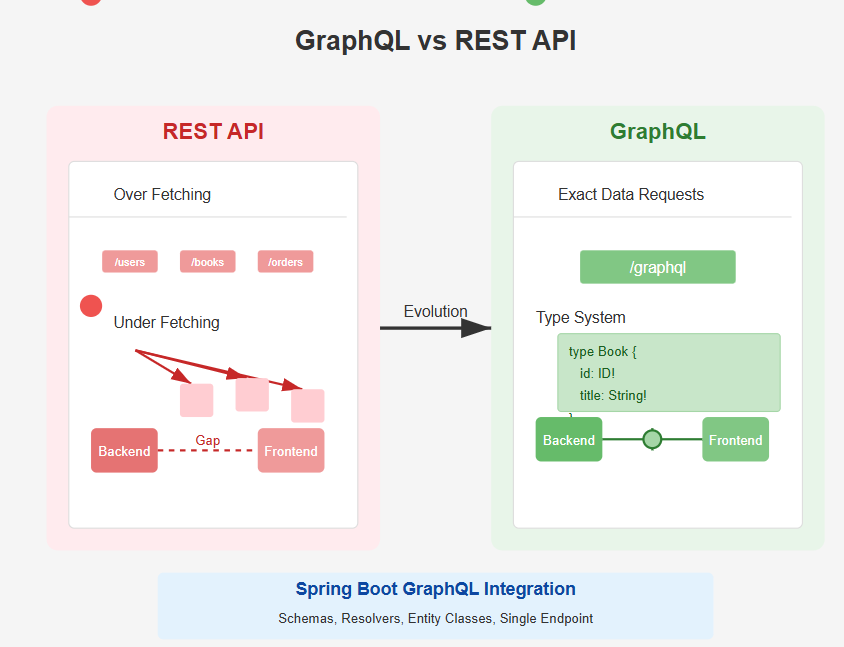
GraphQL은 클라이언트가 필요한 데이터만 요청할 수 있도록 해주는 유연한 쿼리 언어로, REST API와 비교해 오버페칭(Over-fetching) 문제를 효과적으로 해결할 수 있는 잠재력을 지니고 있습니다. 그러나 GraphQL API를 설계할 때 잘못된 접근을 취하면 여전히 성능 저하나 불필요한 리소스 소모를 초래할 수 있습니다. 따라서 GraphQL API 설계 가이드: 오버페칭 방지와 효율성을 바탕으로, 요청에 따라 정확히 필요한 필드만 반환하도록 스키마를 구성하고, 리졸버 성능을 최적화하며, 데이터 로딩 전략을 개선하는 것이 필수적입니다. 특히 중첩 쿼리, N+1 문제, 페이지네이션 미구현 등은 오버페칭의 주요 원인이 되므로, 이를 사전에 방지하는 설계 원칙을 수립해야 합니다.
필드 선택 기반의 스키마 설계
GraphQL의 핵심 장점 중 하나는 클라이언트가 요청하는 필드만 반환된다는 점입니다. 이 기능을 최대한 활용하기 위해서는 스키마를 설계할 때 필드 단위로 세분화된 구조를 유지해야 합니다. 예를 들어, 사용자 정보를 요청할 때 이름, 이메일, 프로필 이미지 등 정보를 하나의 거대한 객체로 반환하는 대신, 각 정보를 개별 필드로 정의함으로써 클라이언트가 필요한 데이터만 선택적으로 요청할 수 있도록 해야 합니다. 이는 GraphQL API 설계 가이드: 오버페칭 방지와 효율성의 기본 원칙 중 하나입니다. 또한, 중첩된 객체의 경우에도 각 하위 필드를 명확히 정의하여 불필요한 데이터를 포함하지 않도록 해야 합니다.
데이터 로더(DataLoader)를 통한 N+1 문제 해결
GraphQL에서는 중첩된 필드 요청 시 N+1 문제가 발생하기 쉽습니다. 예를 들어, 사용자 목록을 요청하면서 각 사용자의 게시물을 함께 요청할 경우, 각 사용자마다 별도의 DB 쿼리가 실행되어 성능 저하로 이어질 수 있습니다. 이를 해결하기 위해 DataLoader와 같은 배치 로딩 기법을 활용해야 합니다. DataLoader는 여러 요청을 한 번에 모아서 단일 DB 쿼리로 처리함으로써 쿼리 효율성을 극대화합니다. 이러한 구현은 GraphQL API 설계 가이드: 오버페칭 방지와 효율성에서 강조하는 백엔드 최적화의 핵심 요소입니다.
필수 및 선택적 필드의 명확한 구분
효율적인 GraphQL API 설계를 위해서는 스키마 내에서 필수 필드(Required Fields)와 선택적 필드(Optional Fields)를 명확히 구분해야 합니다. 필수 필드는 대부분의 클라이언트 요청에서 공통적으로 필요한 데이터를 포함하며, 선택적 필드는 특정 시나리오에서만 요청되는 데이터를 의미합니다. 이 구분을 통해 클라이언트는 불필요한 데이터를 요청하지 않으며, 서버는 불필요한 계산이나 조회를 피할 수 있습니다. 이는 GraphQL API 설계 가이드: 오버페칭 방지와 효율성에서 제시하는 중요한 설계 원칙 중 하나입니다.
쿼리 복잡도 제한 및 비용 분석
클라이언트가 지나치게 복잡하거나 깊이 중첩된 쿼리를 요청할 경우, 서버 자원이 과도하게 소모될 수 있습니다. 이를 방지하기 위해 쿼리 복잡도 제한(Query Complexity Limit)을 도입하거나, 쿼리 비용을 사전에 분석하여 실행을 제어하는 기법을 적용해야 합니다. 예를 들어, 각 필드에 비용 점수를 부여하고, 총 비용이 정해진 한도를 초과하면 요청을 거부하는 방식입니다. 이러한 조치는 GraphQL API 설계 가이드: 오버페칭 방지와 효율성의 보안 및 성능 관리 측면에서 매우 중요합니다.
효율적인 페이지네이션 구현
리스트 데이터를 요청할 때 전체 데이터를 한 번에 반환하는 것은 오버페칭을 초래할 수 있습니다. 따라서 커서 기반 또는 오프셋 기반의 페이지네이션(Pagination)을 적절히 구현해야 합니다. 특히 커서 기반 페이지네이션은 성능이 우수하고 무한 스크롤과 같은 UX에 적합합니다. 페이지 크기를 제한함으로써 클라이언트는 필요에 따라 데이터를 점진적으로 요청할 수 있으며, 서버는 불필요한 데이터 로딩을 방지할 수 있습니다. 이는 GraphQL API 설계 가이드: 오버페칭 방지와 효율성에서 강조하는 데이터 전송 최적화 전략입니다.
| 전략 | 목적 | 적용 예시 |
| 필드 세분화 | 불필요한 데이터 반환 방지 | User 타입 내 name, email, profileImage 분리 |
| DataLoader 사용 | N+1 쿼리 문제 해결 | 사용자별 게시물 조회 시 배치 처리 |
| 쿼리 복잡도 제한 | 서버 자원 과사용 방지 | 중첩 쿼리에 비용 점수 부여 및 제한 설정 |
| 필수/선택 필드 구분 | 요청 효율성 향상 | profileImage를 선택적 필드로 정의 |
| 커서 기반 페이지네이션 | 대량 데이터 효율적 전송 | after 및 first 인자 기반 게시물 요청 |
사례·비즈니스
GraphQL API 설계 시 오버페칭을 방지하는 주요 방법은 무엇인가요?
GraphQL의 핵심 장점 중 하나는 클라이언트가 필요한 필드만 요청할 수 있다는 점입니다. 따라서 오버페칭을 방지하려면 서버 측에서 필드 수준의 해결책(field-level resolution)을 구현하고, 클라이언트 측에서는 정확히 필요한 데이터만 쿼리에 포함하도록 설계해야 합니다. 이는 REST API와 달리 정밀한 데이터 요청을 가능하게 하여 불필요한 네트워크 트래픽과 처리 비용을 줄입니다.
GraphQL에서 데이터 효율성을 높이기 위해 고려해야 할 설계 원칙은 무엇인가요?
효율적인 GraphQL API 설계를 위해서는 타입 시스템의 일관성, resolver 최적화, 그리고 N+1 문제 방지를 위한 데이터 로딩 전략(예: DataLoader 사용)이 중요합니다. 특히, 복잡한 중첩 쿼리가 성능에 미치는 영향을 사전에 분석하고, 필요 시 쿼리 깊이 제한이나 비용 기반 제한(cost-based limiting)과 같은 보호 메커니즘을 도입해야 합니다.
오버페칭과 언더페칭 중 GraphQL에서 더 많이 발생하는 문제는 무엇인가요?
GraphQL은 기본적으로 오버페칭 문제를 해결하기 위해 설계되었기 때문에, 잘 구성된 스키마와 쿼리 하에서는 오버페칭이 거의 발생하지 않습니다. 반면, 언더페칭(under-fetching)은 클라이언트가 필요한 필드를 명시하지 않거나, resolver 간 의존성이 복잡할 경우 발생할 수 있으나, 이는 적절한 스키마 설계와 쿼리 최적화로 충분히 관리할 수 있습니다.
GraphQL API에서 쿼리 성능을 모니터링하고 최적화하려면 어떻게 해야 하나요?
쿼리 성능을 최적화하기 위해서는 먼저 쿼리 복잡도 분석과 실행 시간 측정을 통해 병목 지점을 파악해야 합니다. 이를 위해 APQ(Automatic Persisted Queries), 쿼리 캐싱, 그리고 지표 기반 로깅(metrics-based logging)을 활용하는 것이 좋습니다. 특히, 필드별 실행 시간과 데이터 로딩 지연을 추적하여 resolver 효율성을 지속적으로 개선하는 것이 핵심입니다.